PDF线性化
 PDF线性化(PDF Linear)也称快速Web查看(faster web viewer)。其宗旨就是在一个网络环境中达到有效增量访问,不需要完整下载文件即可阅读的要求。也即我们通常所说的按需下载或者按页下载。
PDF线性化(PDF Linear)也称快速Web查看(faster web viewer)。其宗旨就是在一个网络环境中达到有效增量访问,不需要完整下载文件即可阅读的要求。也即我们通常所说的按需下载或者按页下载。
线性化的优点
- 尽可能快地显示第一页,当通过网络访问PDF文件时,Acrobat Reader会先检测此PDF文件是不是经过线性化处理的,如果则先下载线性化信息,并根据线性化信息得到第一页的数据的位置,然后开始下载第一页的数据并显示,从而不需要等到整个文件下载完毕(非线性化的文件则需要等到整个文件下载结束后才能显示第一页)。
- 尽可能快的完成页跳转。在线性化信息中还包含PDF文件中每一页数据的开始和结束位置,当需要在页间跳转时,Acrobat Reader根据线性化信息的提示准确得到目标页的数据位置和长度并下载,下载完成后即可显示这一页,不会去下载任何多余的数据。从而达到最快的跳转速度及按需下载的目标。
- 增量显示。当网络速度较慢时,Acrobat Reader根据线性化信息的提示尽可能优先显示最有用的数据。
- 优先用户交互。即使在页的内容还未完全显示时,如果有交互操作(如点击链接)则会立即执行交互任务。
- 自动下载。当用户在浏览已下载页的内容时,还未下载到客户端的内容则会在后台自动下载。
线性化PDF文件访问过程
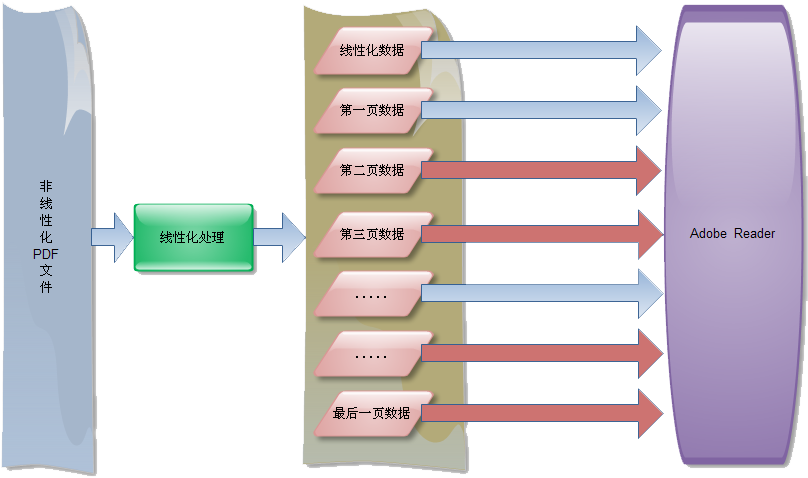
- 经过线性化处理的PDF文件,将每页显示时需要的数据集中存放,以便在一次请求之后即可下载到所有需要的数据。同时将每页的信息做一个索引放在线性化数据中。
- 在用户开始访问文件后,Adboe Reader产生从PDF文件开始处(前1024个字节内)得到线性化数据在PDF文件中的位置及长度,然后发送一个请求下载线性化数据。
- 从线性化数据中得到显示第一页需要下载的数据的位置及长度并下载,下载完成后立即显示这一页
- 在用户浏览已下载页的内容时,Adobe Reader会自动下载其它还未下载到客户端的页的数据
- 当用户跳转到其它页时,Adobe Reader会先检测这个页的数据是否下载,如果没有下载,则从线性化数据中取出这个页数据的开始位置和长度,并发送请示下载。如果已下载则直接显示
经过线性化处理的PDF文件在用Adobe Reader在线浏览时,不必等到文件下载完成后,就可看到文件的内容,当用户在页间切换和跳转时,也不用等待过多的时间,因为只要下载目标页的数据即可显示。特别是在一个速度慢或访问量大的的网络环境中,线性化的优点将会更好地的显现。