PDF单词粘连
 所谓“PDF单词粘连”,就是某些文本型的PDF文件,当用Adobe Reader(或其它任何能打开PDF文件的软件)打开浏览时,看到的内容没有任何异常。但是当从里面复制英文段落时,对于英文部分得到是一串连在一起的英文字母,英文单词之间的空格都丢失了。无论粘贴对象是Word还是UltraEdit或记事本,都是一样的结果。对于这样的PDF文件,不论用什么PDF浏览器,诸如Adobe Reader、FoxitReader还是什么Apabi或CajViewer。这样的PDF文件虽然不影响浏览,但是不能对英文内容创建索引,所以也不能检索。
所谓“PDF单词粘连”,就是某些文本型的PDF文件,当用Adobe Reader(或其它任何能打开PDF文件的软件)打开浏览时,看到的内容没有任何异常。但是当从里面复制英文段落时,对于英文部分得到是一串连在一起的英文字母,英文单词之间的空格都丢失了。无论粘贴对象是Word还是UltraEdit或记事本,都是一样的结果。对于这样的PDF文件,不论用什么PDF浏览器,诸如Adobe Reader、FoxitReader还是什么Apabi或CajViewer。这样的PDF文件虽然不影响浏览,但是不能对英文内容创建索引,所以也不能检索。
产生单词粘连的原因
单词粘连的原因是字符的宽度信息不正确。在PDF内部,没有通常意义上的“
空格”来分隔单词,单词之间的空格是靠字符之间的距离来判断并添加的,在执行判断时,需要使用字符的宽度信息,这个信息来自于PDF中对字体的描述,而不是我们在页面上看到的字符的实际宽度,在正常字体中,宽度信息应比实际宽度大一些,大多少没有统一的标准,所有出现单词粘连问题的PDF文件中,都是宽度信息比实际宽度大很多。如下图中所示,蓝色区域是字符"e"的宽度信息,它比"e"的实际宽度要大很多,以宽度信息是无法界定在"e"和后面的"v"之间应添加一个空格的。
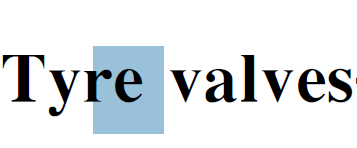
修复结果
如下图中的页面,在修复之前复制得到的是一串连在一起的字母。而修复之后呢,我们得到的是清晰的单词。

修复之前复制得到的结果,可以看到每一行中所有的单词都是连成一串,不具备可读性。
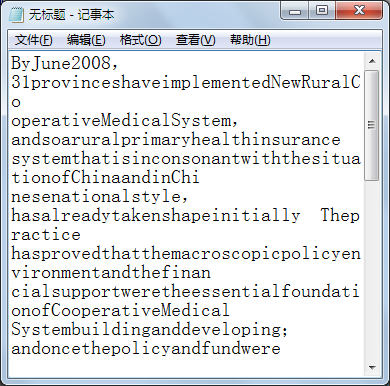
这是修复之后复制得到的结果,可以看到所有的单词都被正确地用空格隔开,可以进行阅读和建立索引。

修复策略
在修复的过程,有一条基本原则是,不能破坏原始的版面,即修复后的PDF文件在浏览时与原始PDF文件有相同的呈现效果,另外在修复 过程不需要人为干预,软件自动判断字体是否存在问题,对于存在问题的字体,根据问题现象分类进行修复,包括调整字体和版面,然后输出正确的文件。为了保证修复不破坏原始PDF文件的版面,每个文件修复完成后,都会与原始文件进行比较,以确认是否在修复过程导致文件被破坏,并产生一个日志文件保存每个文件的结果。
修复要求
PDF文件在修复之前不能存在乱码问题,原因是在判断一个字体是否是存在问题时,需要使用字符的正确编码,如果编码不正确,则修复结果是不可预期的。是否存在乱码问题及修复过程请浏览
PDF乱码修复
样例文件
[原始文件][修复结果]